AI Text Data Training and Other Scaling Problems and Limits | NextBigFuture.com
Unnamed OpenAI researchers told The Information that Orion (aka GPT 5), the next OpenAI full-fledged model release, is showing a smaller performance jump than the one seen between GPT-3 and GPT-4 in recent years. On certain tasks, the Orion model is not reliably better than its predecessor according to unnamed OpenAI researchers.
eX-OpenAI co-founder Ilya Sutskeve stated that LLMs were hitting a plateau in what can be gained from traditional pre-training.
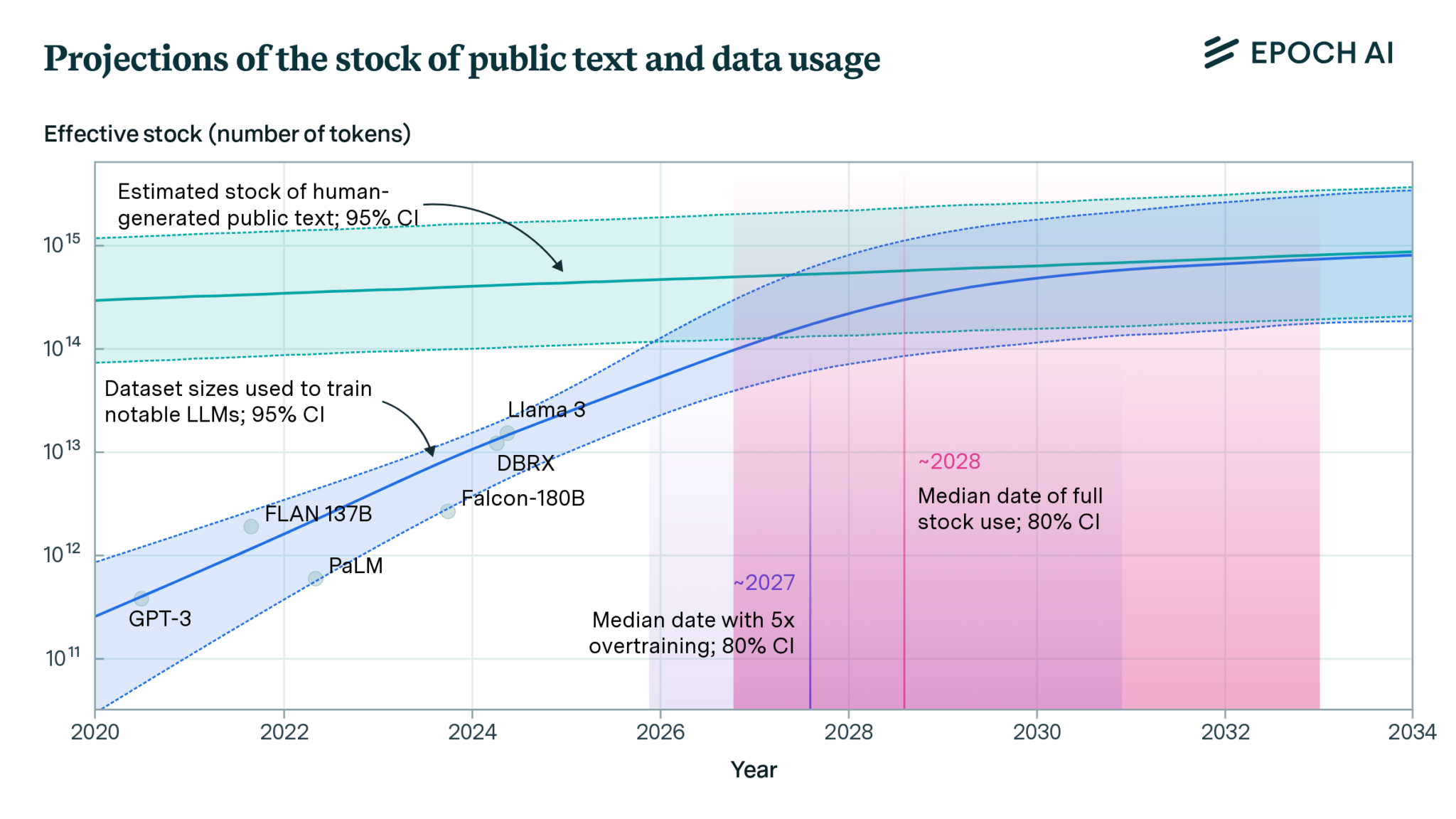
A large part of the training problem, according to experts, is a lack of new, quality textual data for new LLMs to train on.
Epoch describes limitations around 100 trillion to 1000 trillion tokens.
There are many types of data beyond human-generated publicly-available text data, including images and video, private data such as instant messaging conversations, and AI-generated synthetic data. Epoch AI chose to focus on public human text data for three reasons:
Text is the main modality used to train frontier models and is more likely to become a key bottleneck, as other modalities are easier to generate (in the case of images and video) or have not demonstrated their usefulness for training LLMs (for example, in the case of astronomical or other scientific data).
AI-generated synthetic data is not yet well understood, and has only been shown to reliably improve capabilities in relatively narrow domains like math and coding.
Non-public data, like instant messages, seems unlikely to be used at scale due to legal issues, and because it is fragmented over several platforms controlled by actors with competing interests.
Epoch AI estimates the training compute used by frontier AI models has grown by 4-5 times every year from 2010 to 2024. This rapid pace of scaling far outpaces Moore’s law. It has required scaling along three dimensions:
1. making training runs last longer;
2. increasing the number of GPUs participating in each training run;
3. utilizing more performant GPUs.
Epoch AI calculates, the the linear scaling regime of increasing model scales and cluster sizes without substantial declines in utilization will come to an end at a scale of around in a business-as-usual scenario. With the largest known model so far being estimated to have used around , and with the historical rates of compute scaling of around 4-5x per year, we’ll hit the threshold in around 3 years.
Pushing this threshold out by hardware improvements seems challenging, even by just one order of magnitude. We will need substantial and concurrent improvements in memory bandwidth, network bandwidth, and network latency. A more promising way to overcome this threshold appears to be more aggressive scaling of batch sizes during training. The extent to which this is possible is limited by the critical batch size, whose dependence on model size for large language models is currently unknown to us, though we suspect leading labs already have unpublished critical batch size scaling laws.
Energy, Chip, Data and Latency Limits from Epoch AI
Jaime Sevilla et al. (2024), “Can AI Scaling Continue Through 2030?”. Published online at epoch.ai. Retrieved from: ‘https://epoch.ai/blog/can-ai-scaling-continue-through-2030’ [online resource]
Power constraints. Plans for data center campuses of 1 to 5 GW by 2030 have already been discussed, which would support training runs ranging from 1e28 to 3e29 FLOP (for reference, GPT-4 was likely around 2e25 FLOP). Geographically distributed training could tap into multiple regions’ energy infrastructure to scale further. Given current projections of US data center expansion, a US distributed network could likely accommodate 2 to 45 GW, which assuming sufficient inter-data center bandwidth would support training runs from 2e28 to 2e30 FLOP. Beyond this, an actor willing to pay the costs of new power stations could access significantly more power, if planning 3 to 5 years in advance.
Chip manufacturing capacity. AI chips provide the compute necessary for training large AI models. Currently, expansion is constrained by advanced packaging and high-bandwidth memory production capacity. However, given the scale-ups planned by manufacturers, as well as hardware efficiency improvements, there is likely to be enough capacity for 100M H100-equivalent GPUs to be dedicated to training to power a 9e29 FLOP training run, even after accounting for the fact that GPUs will be split between multiple AI labs, and in part dedicated to serving models. However, this projection carries significant uncertainty, with our estimates ranging from 20 million to 400 million H100 equivalents, corresponding to 1e29 to 5e30 FLOP (5,000 to 300,000 times larger than GPT-4).
Data scarcity. Training large AI models requires correspondingly large datasets. The indexed web contains about 500T words of unique text, and is projected to increase by 50% by 2030. Multimodal learning from image, video and audio data will likely moderately contribute to scaling, plausibly tripling the data available for training. After accounting for uncertainties on data quality, availability, multiple epochs, and multimodal tokenizer efficiency, we estimate the equivalent of 400 trillion to 20 quadrillion tokens available for training by 2030, allowing for 6e28 to 2e32 FLOP training runs. We speculate that synthetic data generation from AI models could increase this substantially.
Latency wall. The latency wall represents a sort of “speed limit” stemming from the minimum time required for forward and backward passes. As models scale, they require more sequential operations to train. Increasing the number of training tokens processed in parallel (the ‘batch size’) can amortize these latencies, but this approach has a limit. Beyond a ‘critical batch size’, further increases in batch size yield diminishing returns in training efficiency, and training larger models requires processing more batches sequentially. This sets an upper bound on training FLOP within a specific timeframe. We estimate that cumulative latency on modern GPU setups would cap training runs at 3e30 to 1e32 FLOP. Surpassing this scale would require alternative network topologies, reduced communication latencies, or more aggressive batch size scaling than currently feasible.
Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Information contained on this page is provided by an independent third-party content provider. This website makes no warranties or representations in connection therewith. If you are affiliated with this page and would like it removed please contact editor @riverton.business





